Python 네이버 최저가 구하기 - 3 (자주 쓰는 항목 파일로 정리하기)
네이버 API키를 성공적으로 받았다면 이제 자주 사용하는 항목을 파일로 정리하자. 이번에도 settings 파일을 만들자! 1. settings_naver.xlsx 파일을 만들자. 2. 검색어를 넣을 시트를 만들자. 3. 자주 사
udangco-coding-record.tistory.com
이번에 할 일은 settings_naver.xlsx에 있는 keyword로 네이버에 검색해서 자료를 가져오기이다.
키워드로 검색한 자료를 가져와 보자
1. 새로운 py 파일 만들기
- pycharm에서 왼쪽 파일 트리가 있는 곳에 마우스 우클릭 => New => Python File 클릭
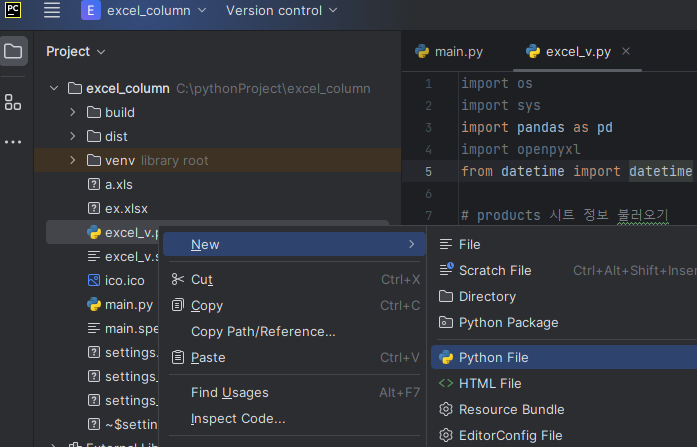
- 파일명 입력하고 엔터 (naver_low로 만들겠다)

2. settings_naver.xlsx 읽어오기
import os
import sys
import pandas as pd
import openpyxl
from datetime import datetime
# keyword 시트 정보 불러오기
keyword = pd.read_excel('settings_naver.xlsx', sheet_name='keyword')
keywords = keyword['keyword'].to_list() # keyword 정보 리스트로 만들기
# basic_info 시트 정보 불러오기
basic_info = pd.read_excel('settings_naver.xlsx', sheet_name='basic_info') # basic_info 시트 불러오기
basic_list = basic_info['set'].to_list() # set 열에 있는 정보 리스트로 만들기
l_price = basic_list[0] # 가격이 있는 열 제목
p_display = str(basic_list[1]) # 수집할 상품 개수 스트링으로 변경
p_sort = basic_list[2] # 정렬기준이제 익숙해졌을 것이다.
특이사항으로 수집할 상품 개수가 숫자로 되어 있는데, 이것을 숫자로 적용시키면 오류가 나니 스트링으로 변경시켰다.
일전에 소수는 float, 정수는 int라고 배웠다.
하나 더 배워가자.
str: 스트링으로 같은 말은 텍스트이다.
3. 네이버 API의 ID와 Secret도 값도 미리 입력해 두자
# api 연결 정보
client_id = '여기에 그대로 복붙'
client_secret = '여기에 그대로 복붙'4. 인터넷으로 정보를 보내고 가져올 수 있는 라이브러리를 설치하자 (requests)
라이브러리 설치 방법은 이전 글 참고
Python excel 열 추출하기 - 1 (라이브러리 설치)
Pycharm 기본 설정 이제 pycharm을 설치했으니 프로그램을 만들어 보자. 만들기 전에 기본 설정이 필요하다. 나는 업무를 하면서 회사 DB에 있는 엑셀 파일을 다운 받아서 다른 곳에 업로드 하거나,
udangco-coding-record.tistory.com
requests로 검색해서 설치하자.

5. 최상단에 import 해주자
import urllib
import requests
6. 최종 파일에 들어갈 데이터프레임(엑셀파일형식)을 만들자
df = pd.DataFrame()
7. for 문을 이용해서 키워드 하나씩 결과를 가져오라고 요청해 보자
for i in range(len(keywords)):
query = keywords[i] # 키워드를 query 변수에 넣자.
query = urllib.parse.quote(query) # query를 api에 적합한 형태로 변형하자.
url = "https://openapi.naver.com/v1/search/shop?query=" + query + "&display=" + display + "&sort=" + p_sort # 네이버 api키를 불러오는 형식
request = urllib.request.Request(url) # 네이버에 url 주소로 연결 요청
request.add_header('X-Naver-Client-Id', client_id) # 네이버 개발자에서 받은 ID를 같이 보내자.
request.add_header('X-Naver-Client-Secret', client_secret) # 네이버 개발자에서 받은 secret을 같이 보내자.
response = urllib.request.urlopen(request) # 응답 받은 정보를 하나의 변수에 넣자.
print(response) # 결과를 출력해 보자.구조는 간단하다.
- keyword의 개수를 카운트해서 그만큼 반복한다. for i in range(len(keywords)):
- len은 keywords 리스트의 값들이 몇 개 있는지 카운트하는 것
- range는 말 그대로 범위. 즉 카운트 한 만큼 반복시키기 위해서 사용
- 키워드를 url에 넣을 수 있도록 적합한 형태로 변형한다.
- keywords의 i 번째 값을 가져와서 url에 넣을 수 있는 정보로 변형해 준다. 그냥 텍스트로 때려 넣으면 안 된다.
- 궁금하다면 실험하기
- 네이버가 원하는 형식으로 물어봐야 한다.
자세히 알고 싶다면 아래 링크 참고
https://developers.naver.com/docs/serviceapi/search/shopping/shopping.md
검색 > 쇼핑 - Search API
검색 > 쇼핑 쇼핑 검색 개요 개요 검색 API와 쇼핑 검색 개요 검색 API는 네이버 검색 결과를 뉴스, 백과사전, 블로그, 쇼핑, 웹 문서, 전문정보, 지식iN, 책, 카페글 등 분야별로 볼 수 있는 API입니다
developers.naver.com
나는 자세히 알고 싶지 않다. 그냥 동작하기만 하면 된다.
reponse변수에 응답받을 정보를 하나의 변수에 넣고 어떤 형식으로 받아오는지 확인해 보자. (print 사용)

뭔가 된 것 같은데 알 수 없는 언어로 나온다.
8. 알아먹을 수 있는 언어로 가져오자.
info_text = response.read().decode('utf-8') # 응답 받은 정보를 한글로 잘 나오도록 하자.
print(info_text) # 잘 출력되는지 확인하자결과는 아래와 같이 잘 나온다.
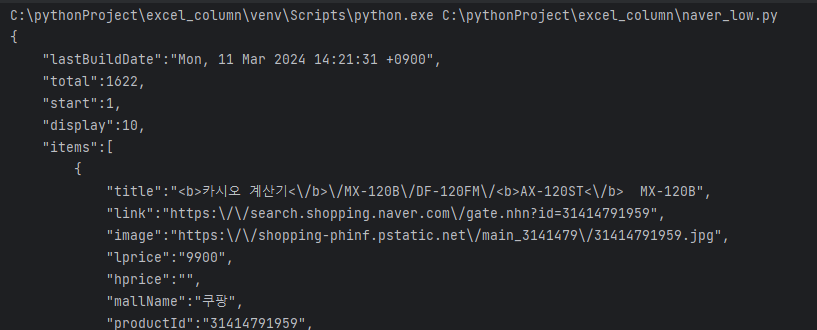
9. 가공할 수 있는 정보로 변형하자.
info_dic = eval(info_text) # 응답 받은 정보를 가공할 수 있는 정보로 바꾸자
print(info_dic)
중괄호로 쌓여 있는 정보들이 나온다. 딕셔너리 형태라고 부르는데 딕셔너리와 리스트에 대해서는 아래 링크를 참고하자.
파이썬 리스트란?
프로그램을 만들다 보면 리스트를 많이 사용하게 된다. 리스트, 튜플, 딕셔너리, 셋 등 개념이 나온다. 나는 가장 많이 사용했던 리스트와 딕셔너리의 개념에 이야기 하겠다. 알고 보면 쉬운 녀
udangco-coding-record.tistory.com
10. items 부분만 추출하자
이전 구조를 잘 보면 items 아래에 내가 원하는 정보들이 있는 것을 볼 수 있다.
info_data = info_dic.get('items') # items만 뽑아보자.
print(info_data)
정보들이 나온다.
전체코드
import os
import sys
import pandas as pd
import openpyxl
from datetime import datetime
import urllib
import requests
# api 연결 정보
client_id = '여기에 그대로 복붙'
client_secret = '여기에 그대로 복붙'
# keyword 시트 정보 불러오기
keyword = pd.read_excel('settings_naver.xlsx', sheet_name='keyword')
keywords = keyword['keyword'].to_list() # keyword 정보 리스트로 만들기
# basic_info 시트 정보 불러오기
basic_info = pd.read_excel('settings_naver.xlsx', sheet_name='basic_info') # basic_info 시트 불러오기
basic_list = basic_info['set'].to_list() # set 열에 있는 정보 리스트로 만들기
l_price = basic_list[0] # 가격이 있는 열 제목
p_display = str(basic_list[1]) # 수집할 상품 개수 스트링으로 변경
p_sort = basic_list[2] # 정렬기준
# 최종 파일에 들어갈 데이터프레임 만들기
df = pd.DataFrame()
display = p_display
# 최저가 검색 후 추출
for i in range(len(keywords)):
query = keywords[i] # 키워드를 query 변수에 넣자.
query = urllib.parse.quote(query) # query를 api에 적합한 형태로 변형하자.
url = "https://openapi.naver.com/v1/search/shop?query=" + query + "&display=" + display + "&sort=" + p_sort # 네이버 api키를 불러오는 형식
request = urllib.request.Request(url) # 네이버에 url 주소로 연결 요청
request.add_header('X-Naver-Client-Id', client_id) # 네이버 개발자에서 받은 ID를 같이 보내자.
request.add_header('X-Naver-Client-Secret', client_secret) # 네이버 개발자에서 받은 secret을 같이 보내자.
response = urllib.request.urlopen(request) # 응답 받은 정보를 하나의 변수에 넣자.
info_text = response.read().decode('utf-8') # 응답 받은 정보를 한글로 잘 나오도록 하자.
info_dic = eval(info_text) # 응답 받은 정보를 가공할 수 있는 정보로 바꾸자
info_data = info_dic.get('items') # items만 뽑아보자.
다음 시간에는 이 정보들을 데이터프레임에 집어넣고 필요 없는 것들을 제거해 보자.
Python 네이버 최저가 구하기 - 5 (데이터프레임으로 정리하기)
네이버 데이터를 열심히 불러와봤다. 데이터프레임으로 정리해보자. for문에 이어서 그대로 작성하자. 이전코드 import os import sys import pandas as pd import openpyxl from datetime import datetime import urllib import
udangco-coding-record.tistory.com
'파이썬' 카테고리의 다른 글
| Python 네이버 최저가 구하기 - 6 (정리 시트 만들기) (2) | 2024.03.12 |
|---|---|
| Python 네이버 최저가 구하기 - 5 (데이터프레임으로 정리하기) (0) | 2024.03.11 |
| Python 네이버 최저가 구하기 - 3 (자주 쓰는 항목 파일로 정리하기) (0) | 2024.03.11 |
| Python 네이버 최저가 구하기 - 2 (네이버 api키 발급) (0) | 2024.03.11 |
| Python 네이버 최저가 구하기 - 1 (설계하기) (4) | 2024.03.11 |



